
ローカルLLM(Ollama)+ChromaでRAGチャットボット構築:ハマりポイント5連発と最終アーキテクチャ
こんにちは、yukiです。
今回は、ローカルLLM(Ollama)+ChromaDBでRAGチャットボットを作った実験ログを、成功談じゃなく「ハマったポイント」「設計ミス」「直し方」に寄せてまとめます。
題材はちょっと特殊で、RAG対象はExcelのデータ。スキル名(例:バハムートクロウ)で検索して、該当行を根拠として回答するCLI型チャットボットをPythonで作りました。
最初は「お、動くじゃん」で終わるんですが、会話が始まった瞬間に一気に壊れます。ここからが本番でした。
なぜローカルRAGを作ろうと思ったのか
理由はシンプルで、手元のExcel(攻略メモ的なやつ)を自然文で引けるようにしたかったからです。
クラウド前提のRAGでもいいけど、今回は「ローカルで完結」「データを外に出さない」「試行錯誤が速い」を優先して、Ollama+Chromaの構成にしました。
- LLM:Ollama(gemma3:12b)
- Vector DB:ChromaDB
- 実装:Python
- データ:Excel(行単位でチャンク化)
- UI:CLIチャット
最初はうまくいった(EVIDENCE_MODE)
初期構成はこうです。
- Excelを読み込んで行ごとにドキュメント化
- Chromaに投入(embedding→保存)
- ユーザー入力から「topic(スキル名)」を抽出
- topicで検索して、ヒットした行を根拠に回答
ここで気持ちよかったのが、**EVIDENCE_MODE(根拠必須)**です。
「根拠が取れなかったら回答しない」を強制すると、嘘を減らせます。
ログの雰囲気はこんな感じ。
[EVIDENCE_MODE] topic=バハムートクロウ
retrieved=3
answer=…(根拠つき)
この時点では「RAGってこういうもんだよね」で終わってました。
でもすぐ壊れた(ここから本番)
壊れる原因は、ベクトル検索そのものというより、会話を成立させるための制御ロジックでした。
RAGは「検索」より「制御」が本質。ここを甘く見ると、Botが急にバカになります。
以下、僕が踏んだ地雷を順に書きます。
問題①:一致必須が強すぎる(曖昧に弱い)
最初のtopic抽出は厳密寄りでした。スキル名が一致しないと検索しない。
結果、こういう質問が死にます。
- 「なんとかクローってどうするんだっけ?」
- 「クローのやつ、どのタイミング?」
topicが取れない=検索できない=EVIDENCE_MODEだと無言、みたいな硬さになる。
ここで導入したのが INFERENCE_MODE(推測モード) でした。
- topicが曖昧でも、近い候補を推定して検索を走らせる
- ただし「推測である」ことは明示する
この瞬間、体感でユーザビリティは上がります。
一方で、推測は危険です。次の地雷に繋がります。
問題②:推測ラベルが二重に出る(設計の責務分離ミス)
推測モードを入れたら、回答の先頭に【推測】を付けたくなる。
でも僕は、
- アプリ側でも【推測】を付ける
- LLMプロンプト側でも「推測なら推測と書け」と指示する
を同時にやってしまい、結果こうなりました。
【推測】【推測】たぶん対象は〜
頭悪くなった…ってなりました。
原因は単純で、表示責務が二箇所に分散してた。
ここは割り切って、ラベル付与はアプリ側に一本化しました。
- LLMには「推測/断定」みたいな装飾をさせない
- LLMの仕事は「与えた根拠から説明する」だけ
RAGの制御は、できるだけアプリで握った方が事故りにくいです。
問題③:followup判定が壊れる(判定順で即死)
次に壊れたのが followup(前の話題を引き継ぐ)判定。
「それ」「さっきのやつ」みたいな代名詞を拾って、前のtopicを使う仕組みです。
ところが、実際には「それ」を言ってないのに対象不明エラーが出る。
- followup=True なのに current_topic=None
- つまり「引き継ぐ」判定だけ立って、引き継ぐ対象がない
ログ的にはこんな感じ。
followup=True / current_topic=None
-> 対象不明です
原因は判定順のミスでした。
僕は「followup判定 → topic抽出」みたいな順で処理していて、topicが確定する前に「引き継ぐぞ!」判定だけ走っていた。
修正は2つです。
- topic抽出 → followup判定 の順にする
- 「それ」ルートに入るのは 代名詞がある時だけ に限定する
この変更だけで、会話の安定性が目に見えて上がりました。
RAGって検索以前に「会話状態マシン」なんだな、と痛感した瞬間です。
問題④:雑談がRAGに流れる(Botが急にバカになる)
さらにしんどかったのがこれ。
- 「いいね」
- 「別の質問でもいい?」
- 「ありがとう」
みたいな発話まで検索に流れて、Chromaに投げる。
当然、変な検索結果が出るか、ゼロ件でEVIDENCE_MODEに弾かれて、会話がギクシャクします。
ここで入れたのが Intent分類です。
ユーザー入力を先に分類して、検索するかどうかを決める。
僕の分類はこんな感じ。
- QUESTION(質問=検索する)
- FEEDBACK(感想=検索しない)
- META_QUESTION(使い方確認=検索しない)
- CONTROL(リセット等=検索しない/状態操作)
このIntent分類を入れた瞬間、世界が変わりました。
RAGが賢くなったんじゃなくて、検索に流す入力がまともになっただけ。
でも、これが一番効きます。
「会話と検索を分離しないとBotはバカになる」って、こういうことでした。
問題⑤:フェーズ質問が検索できない(検索ではなく構造問題)
最後の地雷が一番おもしろかったやつです。
- 「最終フェーズの最後のギミックって何だっけ?」
- 「最終の動きだけ確認したい」
これをtopic抽出すると、topicが「フェーズ」になったりして、検索がゼロ件になります。
当時は「embeddingが弱い?」「チャンクが悪い?」みたいに検索性能のせいにしそうになった。
でも冷静に見ると、これは スキル名検索の問題じゃない。
フェーズ質問は、スキルではなく「どのシート(どの表)」の話か、という参照先解決問題でした。
そこでやったのが、
- 「最終」→ 「金バハTL」 みたいな マッピング
- query_textを拡張して、検索語を補強する(クエリ拡張)
つまり「フェーズ」という単語を必死にベクトル検索するんじゃなく、
検索対象の領域を先に正しく選ぶ方向に寄せました。
これでようやく「フェーズ質問」が安定して拾えるようになりました。
RAGは検索以前に、データの構造と参照設計が支配的です。
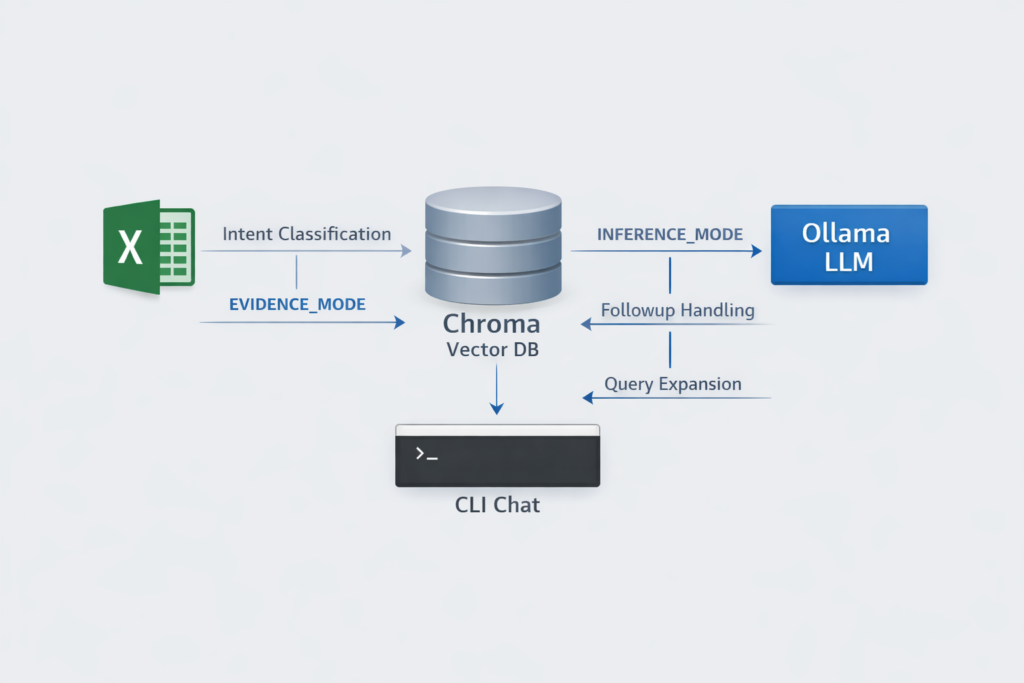
今の設計図(最終アーキテクチャを文章で)
最終的な流れはこんな構成に落ち着きました。
- Intent分類(検索する/しない/状態操作)
- topic抽出(スキル名・別名・曖昧候補)
- followup判定(代名詞がある時だけ前文脈を参照)
- モード決定
- EVIDENCE_MODE:根拠が取れなければ回答しない
- INFERENCE_MODE:候補提示+推測ラベル(表示はアプリ側)
- クエリ拡張
- フェーズ/最終/略称を、シート名や検索語へマッピング
- Chroma検索(必要ならフィルタでシート限定)
- LLM回答生成(根拠を渡し、説明に徹させる)
これで「雑談→検索」みたいな事故が減り、followupも安定し、フェーズ質問も拾えるようになりました。
これからやること
次にやりたいのは、チャットボットを「答える」だけじゃなく、運用で便利にする部分です。
- 質問ログからハマり質問の回数集計(Intent別、topic別)
- 検索ゼロ件の自動抽出→マッピング辞書の改善
- Excel更新時の再取り込みの自動化(差分インデックス)
ここを回し始めると、RAGは「作って終わり」じゃなくて、改善プロセスに入れる感覚が出ます。
学び(最後にまとめ)
今回の実験で、僕が持ち帰ったのはこのあたりです。
- RAGはベクトル検索より「制御ロジック設計」が重要
何を検索に流すか、いつ前文脈を使うか、どこで止めるかで品質が決まる。 - followup判定順を間違えると一気に壊れる
topic抽出より前にfollowupを立てると、対象不明が頻発する。 - 推測は便利だが、制御しないと暴走する
推測ラベルや責務分離をアプリ側で握ると事故が減る。 - 会話と検索を分離しないとBotはバカになる
Intent分類は「検索精度改善」より効くことがある。 - フェーズ質問は検索問題ではなく構造問題
クエリ拡張と参照先(シート/領域)解決でまともに動く。
正直、途中で「頭悪くなった…」って何度も思いました。
でも、壊れ方が見えるほど、RAGの本質が「検索」じゃなく「制御」だと腹落ちしていきました。
同じ構成で作る人がいたら、まずはベクトルDBを磨く前に、Intent→topic→followup→モード→クエリ拡張の順で“壊れにくい道”を作るのが近道だと思います。

- yuki
SIerから社内SEに転職!日々興味を持ったことをつらつらと書いていきます。
まずは、日々の更新を続けることを目標に!
- 【実体験】カード解約しても請求が止まらない?プレイオンラインの請求を止めた方法 2026年2月18日
- Windows11ドメイン環境でOllama社内チャット:IIS ARRの502と“Windowsサービス化”失敗からの現実解 2026年2月17日
- ローカルLLM(Ollama)+ChromaでRAGチャットボット構築:ハマりポイント5連発と最終アーキテクチャ 2026年2月16日
- 赤ちゃんがいる我が家がヘルシオを選んだ話|安心感と置き場所問題のリアル 2026年2月12日
- DNSゾーンが既に登録されています? 2026年2月11日